

Kubernetes: externalTrafficPolicy
En el dinámico mundo de la gestión de contenedores y orquestación, Kubernetes se destaca como una plataforma líder que permite desplegar, escalar y gestionar aplicaciones de manera eficiente.
Entender cómo adapta sus configuraciones de forma genérica para que sea versátil en todo tipo de entornos (EKS, AKS, GKE, sistemas virtualizados o baremetal...etc.), es fundamental para permitir hacer configuraciones avanzadas.
En este artículo, exploramos un concepto que afecta directamente a la gestión del tráfico en Kubernetes: externalTrafficPolicy.
¿Qué es y para qué sirve?
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
externalTrafficPolicy: Cluster
ExternalTrafficPolicy es una configuración que se aplica a los servicios en Kubernetes (Services) y determina cómo es gestionado el tráfico externo a la red del cluster. Hay dos opciones: Cluster y Local.
- Cluster: el tráfico externo se distribuye entre todos los nodos del cluster, independientemente de la ubicación de los pod en dichos nodos. Esto es útil cuando se busca tener alta disponibilidad con menos pods que nodos, y se desea distribuir la carga de manera uniforme en todos los nodos del cluster. De esta forma se consigue, mediante un componente del cluster de kubernetes (kube-proxy), atender las peticiones de ese servicio enviándolo a los pods alojados en otros nodos de forma transparente.
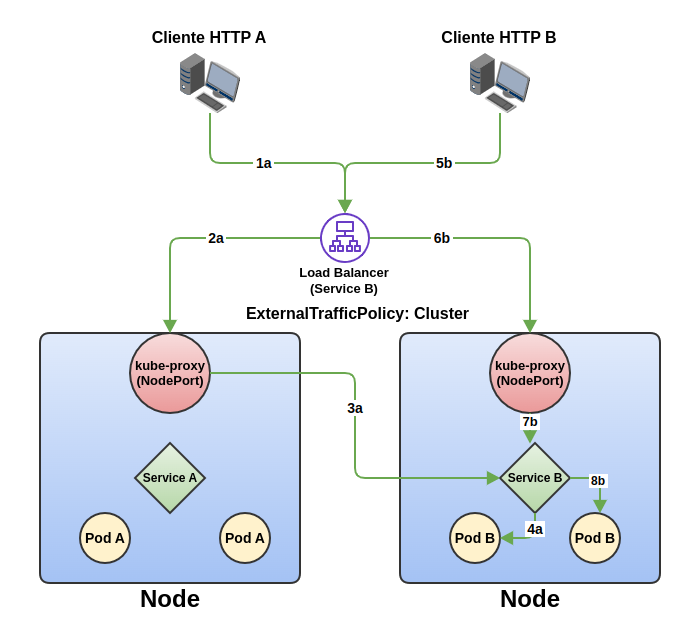
Podemos ver en este ejemplo cómo el cliente A realiza una conexión al servicio B (1a) a través del load balancer. Éste tiene activos los health checks en ambos servidores a pesar de haber un servidor que no dispone de pods del servicio B (el nodo de la izquierda). Por ello, el tráfico es enrutado sin problema a través del nodo de la izquierda (sin pods B) (2a), que mediante kube-proxy, es enviado al Sevice B del nodo de la derecha (3a). Allí el tráfico es enviado al pod correspondiente a través de su Service asociado (4a).
Segundos después, el cliente B realiza una nueva conexión al servicio B a través del load balancer (5b). El balanceador reparte el tráfico al nodo de la izquierda, ejerciendo un buen reparto balanceando la carga (6b). En este caso, kube-proxy envía el tráfico al service B (7b) que a su vez es balanceado a otro pod B disponible (8b), balanceando también la carga en diferentes pods del mismo nodo.
NOTA: Si hubiera algún pod B en ambos nodos, con la configuración de tipo cluster, sería enrutado de forma balanceada a otro nodo sin tener en cuenta que no era “el camino más corto” y de menor latencia. Esto implica que haya respuestas que se dan con mayor latencia sin haber una necesidad por no ser “el camino más corto”, en virtud de un reparto de carga equilibrado entre nodos.
- Local: el tráfico externo se dirige únicamente a los nodos que tienen pods del servicio en ejecución, de forma que no existe reenvío de tráfico de unos nodos a otros ya que no expondrán un servicio que no disponen. Esto puede ser beneficioso cuando se busca reducir la latencia y mejorar la eficiencia al enrutar el tráfico directamente al nodo que hospeda el pod, pero tiene otras desventajas como la pérdida de disponibilidad del servicio temporal si perdemos los nodos que alojan estos pods de forma inesperada.
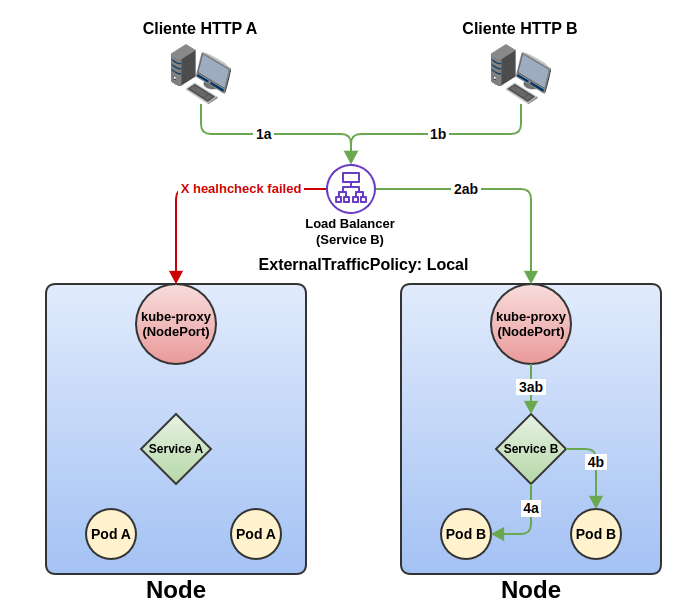
En el ejemplo de esta ilustración con externalTrafficPolicy de tipo Local, el cliente A conecta al servicio B a través de un load balancer (1a). Este balanceador, con la configuración actual, solo tiene un nodo en servicio, ya que los kube-proxy solo responden a peticiones de health check que pueden atenderse en su nodo local. Por ello, el tráfico es enrutado desde el load balancer al nodo de la derecha (2a), que a través de kube-proxy es enviado al service B (3a) y al pod B en servicio (4a). Segundos después, el cliente B abre una conexión al service B a través del load balancer (1b). Al no tener opción, vuelve a enviar el tráfico al nodo de la derecha (2b), que a través de kube-proxy es enviado al service b (3b) y al pod correspondiente de forma balanceada (4b). En este caso vemos que ambos tráficos tienen las mejores latencias por utilizar el camino más corto, pero hemos perdido alta disponibilidad, escalabilidad y un reparto de carga equilibrado entre nodos.
Después de ver estos ejemplos, vamos a analizar las ventajas e inconvenientes de ambos modos.
Ventajas e inconvenientes: Cluster vs Local
- Alta disponibilidad: el modo Cluster garantiza que el tráfico externo se distribuya uniformemente entre todos los nodos, mejorando la disponibilidad de la aplicación.
- Escalabilidad: el modo Cluster facilita la escalabilidad al distribuir la carga de manera equitativa en todos los nodos del cluster aunque el reparto de pods no sea equilibrado entre nodos. Un nodo con seis pods y otro nodo con dos pods en modo Cluster garantiza que todos los pods reciban el mismo número equilibrado de conexiones, independientemente del nodo que atienda el tráfico externo.
- Mayor latencia: por contra, el modo Cluster en comparación con Local puede introducir mayor latencia en las peticiones atendidas por un nodo “no Local”, ya que el tráfico puede cambiar de nodo a través de kube-proxy para ser atendido por un pod de otro nodo del cluster. Con el modo Local la latencia siempre será la misma y más rápida en general que en modo Cluster al asegurar que solo va a ser atendida por pods alojados en el propio nodo que recibe el tráfico.
- Forzar reparto de pods entre nodos: al utilizar modo Local, nos podría ocurrir que todos los pods estuvieran agrupados en un subconjunto de nodos sobrecargándolos frente a otros que quedan infrautilizados. En caso de perderlos de forma inesperada, sufriremos una caída temporal del servicio (aún teniendo otros nodos disponibles). Para ello es recomendable utilizar reglas de anti-afinidad en los deployments para permitir un reparto lo más equitativo posible de los pods entre los nodos. De esta forma, forzamos que todos los nodos tengan opción de servicio local al tener pods disponibles en su nodo. Con ello, se evitan pérdidas de servicio por un mal reparto de los pods en los nodos disponibles del cluster y un reparto de carga que no depende del cluster. Podemos ver un ejemplo de configuración de antiafinidad de un deployment mediante hostname.
[...]
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: k8s-app
operator: In
values:
- my-app
topologyKey: kubernetes.io/hostname
[...]
- Preservar ip origen: en modo Cluster no preserva la dirección ip origen del tráfico, por lo que la ip recibida será normalmente la del balanceador o último componente externo que envía el tráfico al pod y no la ip origen. Si tenemos este requerimiento, nos obligará a utilizar el modo Local.
- AWS ALB unhealty nodes: en modo Cluster, debido al mecanismo de respuesta a nivel de red de los pods al tráfico recibido de forma indirecta (basado en SNAT), provoca pérdidas de servicio aleatorias debido a que se pierden las peticiones healthcheck de respuesta que el balanceador no reconoce. Todo apunta a que es debido a un bug de kube-proxy que será subsanado en próximas versiones. Mientras tanto, el “workaround” ofrecido es usar modo Local con todas las consecuencias.
No existe una solución ideal para todas las infraestructuras y casos de uso. Debes evaluar qué opción se ajusta mejor al servicio que ofrece el cluster de Kubernetes en cuestión y minimizar los inconvenientes con otras estrategias.
En cualquier caso, esperamos que estas explicaciones te lleven por el buen camino. Si no lo encuentras y has llegado leyendo hasta aquí, ya sabes dónde encontrarnos :-)