

Alta disponibilidad en PostgreSQL con Patroni (I)
PostgreSQL es el segundo sistema de gestión de base de datos más popular y el más querido por los desarrolladores según la encuesta anual de StackOverflow en 2022. Además está muy vinculado con el desarrollo en python.
En este artículo vamos a configurar un cluster de PostgreSQL con alta disponibilidad.
Alta disponibilidad en PostgreSQL
Para contar con alta disponibilidad en un sistema de base de datos son necesarios dos puntos: replicación entre instancias y un failover automático.
Hay múltiples formas de llevar a cabo replicación entre varias instancias en PostgreSQL y, en la propia documentación, se detallan desde los discos compartidos o sincronización de filesystem hasta Write-Ahead Log Shipping (WAL), que es la que vamos a utilizar nosotros en este artículo.
El failover automático, no obstante, no es una funcionalidad nativa de PostgreSQL, por lo que hay que utilizar otro software para conseguirlo. Dado que se trata de una funcionalidad ampliamente utilizada, existen multitud de productos opensource y libres que nos permiten añadir esta característica a nuestro cluster de PostgreSQL.
Patroni
Una de las opciones más utilizadas y completas para configurar replicación y failover automático en PostgreSQL es Patroni.
Este software ha sido creado por el equipo de Zalando, la popular tienda alemana de moda online, y está publicado bajo la licencia permisiva de software libre MIT.
No se trata de una solución empaquetada y lista para utilizar, ni tampoco que sirva a todo el mundo, más bien como describe el propio equipo “se trata de una plantilla para crear una solución personalizada de alta disponibilidad para PostgreSQL utilizando python y un sistema de configuración distribuida".
Por ese motivo, podemos ver despliegues de Patroni muy diferentes utilizando distintas tecnologías. Por ejemplo, en cuanto a la configuración distribuida, no nos ata a un software concreto, ya que es compatible con ZooKeeper, etcd, Consul o Kubernetes entre otros.
Para la replicación, Patroni utiliza por defecto la replicación en stream nativa de PostgreSQL en modo asíncrono, pero también es posible llevar a cabo otro tipo de configuraciones.
Nuestra solución con Patroni
Teniendo en cuenta esto, lo primero que tenemos que hacer es definir cómo va a ser nuestra solución personalizada. En este caso vamos a desplegar un cluster de 3 nodos con replicación asíncrona utilizando etcd para la configuración distribuida y HAProxy para el acceso a base de datos.
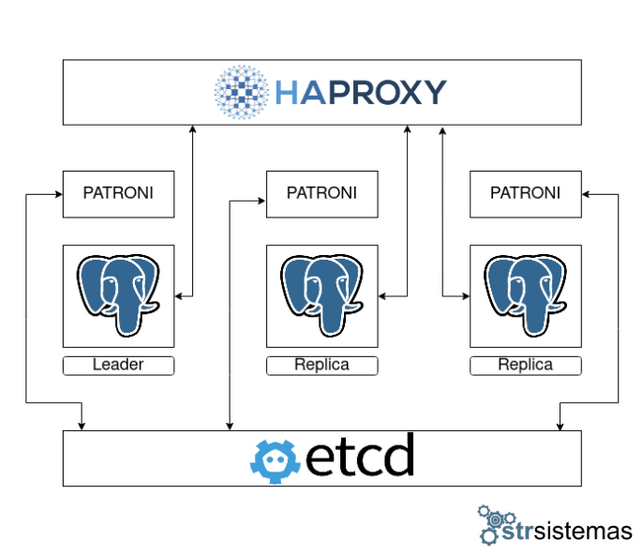
Para nuestro cluster necesitaremos por lo tanto 4 servidores, 3 nodos de PostgreSQL y una instancia de HAProxy para gestionar el acceso al nodo correcto de forma transparente cuando se produzcan los failovers.
Por lo tanto, si vas a seguir nuestra guía, es momento de que levantes cuatro instancias o máquinas virtuales en tu proveedor o sistema preferido con Debian 11 sobre las cuales instalaremos PostgreSQL 13 (Patroni soporta actualmente las versiones 9.3 a 15 de PostgreSQL).
En el próximo artículo explicaremos las configuraciones de etcd y Patroni necesarias para levantar el servicio de PostgreSQL en alta disponibilidad.