

Bloat en PostgreSQL y el uso de vacuum
A menudo el performance de PostgreSQL se degrada con el tiempo cuando existe un alto volumen de lectura/escritura, lo que acaba provocando lentitud. Esto en muchas ocasiones es debido a que se produce el efecto conocido como “bloat”. No obstante, una correcta configuración y mantenimiento de PostgreSQL puede evitar estas situaciones y mantener nuestra base de datos con un rendimiento óptimo.

¿Por qué se genera bloat en PostgreSQL?
Al igual que muchos otros sistemas de base de datos, PostgreSQL está diseñado para permitir consultas de solo lectura de forma concurrente mientras se realizan actualizaciones de los datos. Esto es posible gracias al Multi-Version Concurrency Control (MVCC), un sistema que permite lecturas continuas generando múltiples snapshots de las transacciones y consolidándose finalmente. De esta manera se produce un mayor uso de disco para almacenar dichos snapshots, conociéndose como bloat.
En PostgreSQL el proceso que se utiliza para eliminarlo se conoce como vacuum.
Entrando en más detalle al respecto, toda nueva transacción en PostgreSQL está numerada con un identificador incremental, txid. A su vez, las tablas también contienen unas columnas ocultas, xmin y xmax, que indican los identificadores mínimos y máximos que tienen permitido ver las filas. Las filas que no tienen una transacción activa o pasada que las pueda consultar se consideran muertas.
Por lo tanto, cuando se inserta o actualiza una fila se utiliza el txid de la transacción que realiza la acción como xmin y, cuando se elimina una fila, se utiliza el txid de la transacción que realiza la acción como xmax.
Por este motivo si no se lleva a cabo una acción de vacuum, la base de datos crecerá en tamaño indefinidamente, ya que los registros no se están eliminando, sino que, quedan “muertos”.
¿Cómo afecta el bloat al rendimiento?
Esto no es un problema únicamente por el aumento de ocupación de disco indefinido, el bloat también afecta al rendimiento de la base de datos.
Cada tabla e índice se almacena como un array de páginas con tamaño fijo y, cuando una query solicita las filas, el sistema carga las páginas en memoria. Cuanto mayor volumen de filas muertas haya por página más I/O innecesario se utilizará en la carga.
Estas filas muertas acabarán ocupando espacio en memoria y los escaneos secuenciales seguirán pasando por ellas a pesar de que los datos no puedan ser leídos ya por las nuevas transacciones. Esto causa un consumo de memoria innecesario.
El bloat también afecta a los índices aunque en menor medida en cuanto a rendimiento, ya que son capaces de marcar las tuplas muertas como tal, no obstante el aumento de ocupación sigue siendo alto.
Tuning de autovacuum
Por todo esto es imprescindible configurar de forma correcta el autovacuum en nuestro servicio de PostgreSQL.
Este servicio se encarga de llevar a cabo las acciones de vacuum sobre las tablas e índices cuando se cumplen ciertas condiciones, siendo capaz de pararlas si detecta que está siendo muy intrusivo para no afectar al funcionamiento normal de la base de datos.
El funcionamiento es el siguiente: el servicio de autovacuum intenta arrancar un nuevo worker cada autovacuum_naptime y puede correr como mucho autovacuum_max_workers a la vez. Cada worker busca tablas que cumplan la condición:
- [filas invalidas estimadas] ≥ autovacuum_vacuum_scale_factor * [tamaño de tabla estimado] + autovacuum_vacuum_threshold
Una vez seleccionada una tabla, el worker elimina las tuplas muertas compactando páginas. Para ello, primero escanea las tuplas muertas incluyéndolas en una lista para posteriormente eliminarlas de los índices en las que estén incluidas y finalmente eliminarlas de la heap.
El servicio mantiene un contador de créditos de I/O de tal forma que cuando llega al autovacuum_vacuum_cost_limit se pausa durante el tiempo configurado en autovacuum_vacuum_cost_delay. De esta forma se intenta compaginar el servicio de autovacuum con un correcto funcionamiento de la bbdd. Por este motivo, y dependiendo de la configuración, el autovacuum puede dejar de limpiar correctamente si se están dejando muchas tuplas muertas y no se está asignando suficientes recursos a los workers.
El tuning de autovacuum debe de hacerse atendiendo a las necesidades de cada base de datos en concreto. Por lo tanto es buena idea revisar antes de nada cómo está funcionando y con qué frecuencia se ejecuta con la siguiente query:
SELECT last_autovacuum, autovacuum_count, vacuum_count FROM pg_stat_user_tables;
Con esta información podemos tomar decisiones sobre si es necesario ajustar alguna de las configuraciones. Uno de los problemas más habituales es que el autovacuum no llega a ejecutarse sobre tablas muy grandes debido a que el valor por defecto de autovacuum_vacuum_scale_factor es demasiado bajo. En este caso es buena idea reducir este valor para que no sea necesario un alto número de modificaciones en la tabla para la ejecución ya que esto puede ser después contraproducente al realizar el vacuum.
Además de modificar este valor de forma global en la configuración de PostgreSQL también lo podemos cambiar a nivel de tabla con una query como la siguiente:
ALTER TABLE <tablename>
SET autovacuum_vacuum_scale_factor = 0.02;
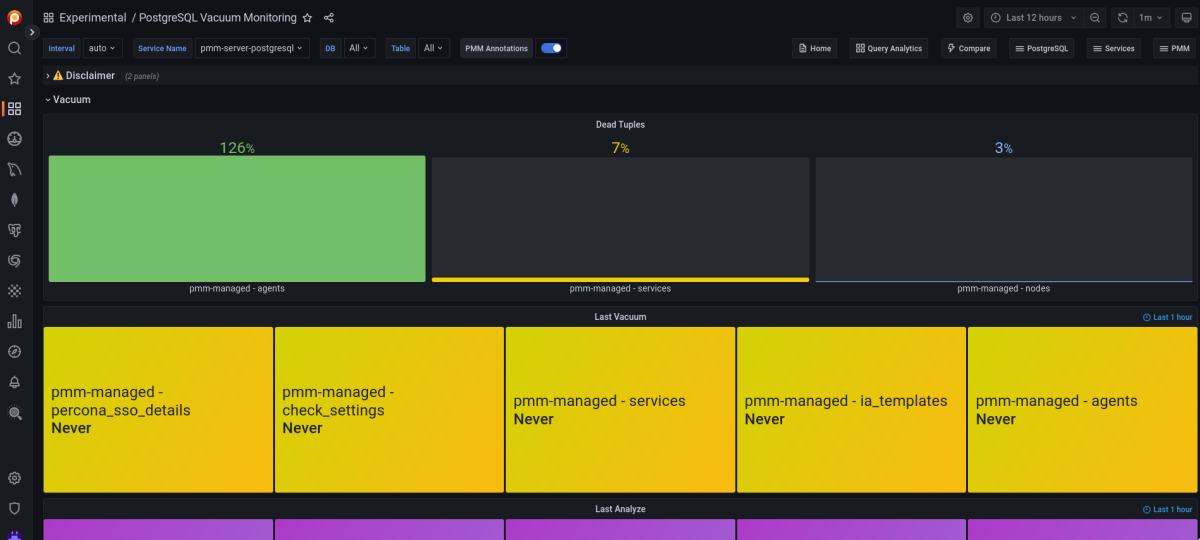
En cualquier caso es recomendable estar al tanto del índice de bloat de las tablas e índices de nuestra base de datos, ya que un cambio en el uso puede hacer que sea necesaria una modificación en la configuración del autovacuum. Podemos comprobar el estado con esta query. Por otro lado, PMM ahora cuenta con un dashboard, todavía en fase experimental, para monitorizar el estado del bloat y los vacuum.
Conclusión
Es necesario estar al tanto del bloat en nuestra base de datos PostgreSQL y configurar el autovacuum en función de nuestras necesidades para mantener un rendimiento óptimo.
Puede ser incluso necesario llegar a hacer un vacuum manual para partir de un buen estado si nuestra configuración de autovacuum no está siendo capaz de seguir el ritmo a la creación de nuevas tuplas muertas.