

Centralizado de logs a fichero con Logstash
Hace unos meses realizamos un interesante artículo titulado Auditar eventos y acciones en sistemas Linux y Windows, donde mostrábamos cómo dejar reflejadas en logs las diferentes llamadas al sistema en máquinas Linux y Windows. Al final de dicho artículo recalcábamos que esta solución sólo contemplaba el tener los logs en local, y que en entornos con varios servidores, lo más conveniente era poder enviar estos logs a un sistema centralizado. Este es el tema que vamos a tratar en el artículo de hoy, centrándonos concretamente en entornos Linux.
Puesto que este artículo es una continuación del mencionado anteriormente, explicaremos cómo centralizar logs del servicio audit, pero debemos destacar que esta solución también es válida para centralizar cualquier tipo de log, ya sea de Apache, Nginx, Tomcat, MySQL o lo que necesitéis.
Pero, ¿por qué es importante tener nuestros logs centralizados en un único lugar?
Imagina que tienes dos servidores web, y en cada uno se generan logs de las peticiones que le llegan. Ahora imagina que estás sufriendo errores 500 esporádicos y para empezar a depurar quieres obtener todas las trazas de estos errores. El procedimiento a seguir sería entrar a un servidor, buscar y filtrar entre los logs, desconectar y entrar al otro servidor para nuevamente buscar y filtrar entre los logs. Y esto es teniendo solamente dos servidores, a más servidores tengas, más tedioso se vuelve el proceso.
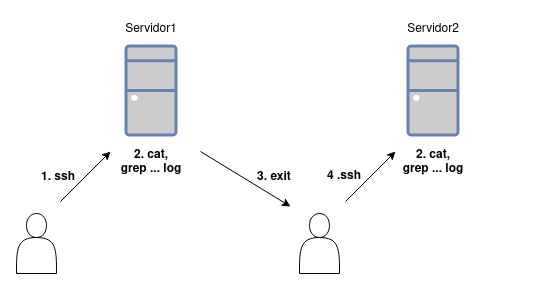
Ahora imagina que además de los servidores web tienes un servidor destinado al centralizado de logs. En éste, aquellos logs que le llegan y que son del mismo tipo se guardan en un mismo fichero unificado, lo único que tendrías que hacer en este caso es entrar a este nuevo servidor y consultar el log centralizado, sin importar que tengas dos o cien servidores web.
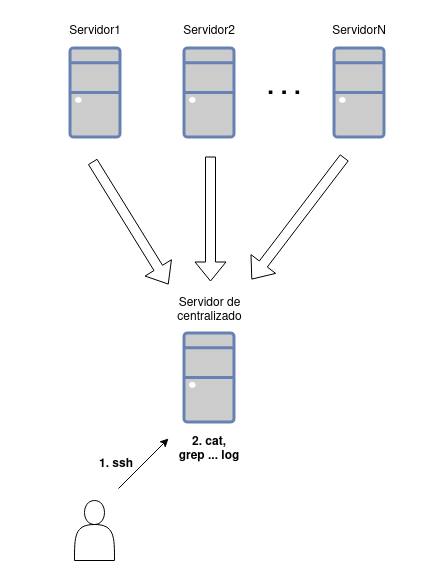
Mucho mejor, ¿verdad? Y... ¿cómo se consigue esto? Realmente existen muchas maneras, pero en este caso vamos a explicar un método que consiste en el uso de Logstash + Redis. Así pues, comenzamos.
¿Qué se necesita?
Lo mínimo para hacer funcionar esta solución es tener instalado lo siguiente en los servidores:
- En el servidor donde se centralizarán los logs:
- Logstash
- Redis
- En los servidores que enviarán los logs:
- Logstash
Para llevar a cabo la instalación de Logstash recomendamos echar un vistazo a su documentación, dado que los pasos varían en función de la distribución que estéis utilizando o de la forma en que queráis correr este servicio (por ejemplo, en un contenedor de Docker). Para instalarlo en Debian, de manera resumida, los pasos serían:
1. Instalar el paquete “apt-transport-https” para poder agregar la clave pública del repositorio.
apt install apt-transport-https
2. Agregar la clave pública como tal.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | gpg --dearmor -o /usr/share/keyrings/elastic-keyring.gpg
3. Agregar el repositorio de Elastic.
echo "deb https://artifacts.elastic.co/packages/8.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-8.x.list
4. Y por último ya solo tienes que hacer un update e instalar Logstash.
apt update
apt install logstash
La instalación de Redis (o mejor dicho, redis-server) es más sencilla ya que la mayoría de distros ya incluyen los paquetes en sus repositorios como es el caso de Debian, así que simplemente lanza lo siguiente y la instalación comenzará:
apt install redis-server
Recomendamos tener en cuenta la línea bind en el fichero de configuración de Redis (/etc/redis/redis.conf), la cuál por defecto tiene este aspecto:
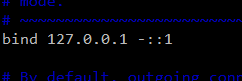
Lo ideal es fijar aquí la IP del servidor en el que está instalado, en su defecto, si se elimina, Redis escuchará en todas las interfaces de red del servidor.
¿Cómo se configura?
Tanto Logstash como Redis, al igual que cualquier servicio, se pueden configurar para que actúen como deseamos. Por ejemplo, para Logstash puedes modificar los límites de la heap, la home de Java si quieres utilizar una versión de JDK diferente a la que trae empotrada, etc. Y para Redis, puedes requerir (o no) una contraseña para poder conectar, puedes modificar el puerto en el que escuchará o puedes saber con qué frecuencia se vuelcan los datos a disco (Redis es una base de datos en memoria), entre otras. Las opciones son numerosas y muy extensas, y de su correcta configuración dependerá que este escenario que estamos planteando funcione.
Quedaría un artículo muy largo si contemplamos todos los casos posibles, por lo que nos vamos a centrar únicamente en las configuraciones del pipeline de Logstash tanto en los servidores que envían logs como en el servidor del centralizado. Para ello, dentro del directorio /etc/logstash deberás crear un fichero .conf (puedes elegir el nombre que quieras). Para los servidores que enviarán los logs al centralizado, añadiremos lo siguiente:
input {
file {
path => [ "/var/log/audit/*.log" ]
type => "auditd"
discover_interval => 5
}
}
output {
if [type] == "auditd" {
redis {
host => "<ip_destino>"
port => 6379
data_type => "list"
key => “<nombre>”
}
}
}
En la sección input es donde definimos de dónde recogerá Logstash la información. En este caso, estamos usando el plugin file para indicarle que recoja las trazas de todos los ficheros .log en /var/log/audit. Le mostramos que todo lo recogido es de tipo “auditd” (enseguida explicaremos por qué) y el parámetro discover_internal se utiliza para indicar con qué frecuencia se escanea el path indicado en busca de actualizaciones en el contenido de los ficheros, y su valor es completamente personalizable.
En la sección output es donde se indica dónde enviar lo recogido. Con el condicional if [type] == "auditd" le estamos diciendo que las acciones definidas dentro del condicional se aplican si las trazas recogidas son de tipo "auditd” (para esto sirve indicar el tipo “auditd” antes, en la sección input). Utilizamos el plugin redis e indicamos el host (que será el servidor de centralizado) y el puerto en el que éste escucha, en “data_type” será “list” para que el comando ejecutado de Redis sea RPUSH, y en “key” damos nombre a la lista de Redis, pudiendo elegir el nombre que deseemos.
Para el servidor del centralizado de logs añadiremos la siguiente configuración en Logstash:
input {
redis {
host => [ "<ip_mi_servidor>" ]
port => 6379
data_type => "list"
key => "<nombre>"
}
}
output {
if [type] == "auditd" {
file {
path => "/logs/auditd/auditlogs.log"
flush_interval => 0
}
}
}
En este caso, el proceso es el inverso: el plugin de redis va en la sección input y el plugin file va en la sección output.
En la parte del plugin redis indicamos la propia IP del servidor y el puerto en el que está escuchando el servicio redis-server que tenemos instalado en el mismo. Por su parte, en el plugin file, indicamos en qué fichero centralizado se guardarán las trazas. Con “flush_interval” se indica el intervalo (en segundos) para ir volcando la información a fichero.
Concluyendo...
En este artículo habéis visto con un ejemplo inicial, la importancia de contar con un sistema centralizado de logs y os hemos dado unas pinceladas de cómo montar un sistema sencillo de centralizado a fichero con Logstash y Redis.
Esperamos que os sea de utilidad, y recordad, como os hemos dicho antes, que en la parte más práctica sólo nos hemos centrado en las configuraciones del pipeline de Logstash y no hemos profundizado en las configuraciones de los servicios como tal, las cuales deberán ser modificadas y ajustadas para cada caso real concreto.