

Estadísticas de tablas en MySQL y su optimización
Cuando nuestras bases de datos van creciendo, ya sea en número de tablas, en número de registros, o ambas cosas, es muy común que empecemos a apreciar una degradación en el tiempo de ejecución de las queries de lectura, especialmente si éstas son complejas y tienen que coger datos de diferentes tablas.
Por suerte, MySQL ofrece opciones para acelerar (optimizar) estas consultas.
Pero antes de pasar a explicar este proceso, vamos a empezar por comprender un concepto básico: ¿cómo elige InnoDB (el motor de almacenamiento que utiliza MySQL) el mejor camino a seguir a la hora de recoger datos? La respuesta es: sirviéndose del contenido almacenado en la tabla statistics.
La tabla statistics y su utilidad
Esta tabla, que se encuentra en la base de datos information_schema, almacena información sobre los índices de todas las tablas del conjunto entero de las bases de datos.
Podemos consultar su contenido mediante la ejecución de:
SELECT * FROM information_schema.statistics;Esta tabla se compone de casi veinte columnas, a destacar:
- SEQ_IN_INDEX. La posición (u orden) de un índice de entre todos éstos que contiene una tabla.
- COLLATION. Cómo se ordena una columna en un índice determinado. Puede tener los valores A (ascendente), D (descendente) o NULL (no está ordenada).
- CARDINALITY. Quizá el valor más importante en lo referente al tema que nos ocupa en este artículo, lo podemos traducir como cardinalidad. Es un dato de tipo numérico (integer) que estima el número de valores únicos que tiene un índice y, cuanto más elevado sea, más probabilidad hay de que InnoDB use ese índice cuando hagamos un JOIN.
Cuando hacemos una consulta SELECT con uno o varios JOIN, InnoDB se basa en los valores almacenados en esta tabla statistics para elegir qué índices va a utilizar y cuáles no (tarea que realiza el planificador de MySQL), para tratar de seguir la “ruta más óptima”, es decir, la que considera más rápida, para recoger los datos.
Es en este momento es cuando a muchos de nuestros lectores se les están pasando dos preguntas por la cabeza:
- ¿Cómo se calcula el contenido de la tabla statistics?
- ¿La ruta elegida es siempre la más óptima?
A la primera pregunta, la respuesta en primer lugar es que puede ser de forma automática o manual. Por defecto se calcula (y recalcula) de manera automática.
Podemos saber si tenemos activada esta opción mediante la siguiente consulta:
SHOW VARIABLES LIKE ‘innodb_stats_auto_recalc’;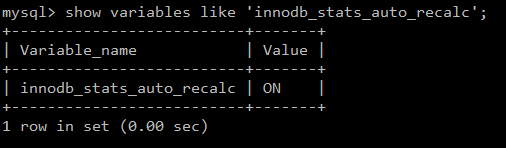
Si está activada, InnoDB recalculará las estadísticas cuando se realicen cambios en al menos el 10% de las filas de una tabla.
En segundo lugar, sobre cómo se realiza este cálculo, InnoDB utiliza la técnica conocida como random dive, que selecciona páginas aleatorias de cada índice para hacer una estimación de la cardinalidad (concepto que hemos visto anteriormente).
Pese a tener la palabra “random” en su nombre, esta técnica no es 100% aleatoria, puesto que las páginas seleccionadas se basan en un algoritmo que emplea la fórmula:
N * R * AVG_LEAF , donde:
- N = el número de páginas hoja.
- R = la relación (o proporción) entre el número de valores clave por nivel de aislamiento y el número total de registros en dicho nivel.
- AVG_LEAF = la media de valores clave encontrados en todas las páginas hoja.
Y para los más pacientes, en el siguiente enlace podéis ver los detalles del algoritmo a lo largo de sus casi 4.000 líneas de código.
Sabiendo todo lo anterior, la respuesta a la segunda pregunta parece obvia: ¿La ruta elegida es siempre la más óptima? Evidentemente, no.
Con un algoritmo en el que entran tantas variables, que coge índices que pueden estar fragmentados y sobre tablas cuyo contenido no para de cambiar, los valores obtenidos no siempre van a ser precisos, ni mucho menos los más óptimos. Incluso puede que lo que en el pasado fue óptimo, haya dejado de serlo con el paso del tiempo y el crecimiento de la base de datos.
Precisamente por este motivo las consultas sobre tablas grandes y con uno o varios JOIN, pueden demorarse más de la cuenta, y es entonces cuando podemos realizar una optimización de dichas tablas.
Optimización de tablas
Para la realización de estos ejemplos hemos creado un escenario ficticio con unas tablas con decenas de miles de registros y de varios cientos de megabytes de ocupación en disco. Éstas tienen dos campos (‘id’ y ‘val’) y hemos creado algunos índices.
Los detalles sobre el contenido de las tablas no son relevantes, lo que nos interesa es lo siguiente.
Supongamos que tenemos la siguiente query:

La lanzamos y el tiempo de ejecución es el siguiente:

Figurémonos que queremos reducir este tiempo de ejecución.
Para consultas complejas donde intervengan varias tablas, podemos lanzar el comando EXPLAIN para que nos indique información de cómo el planificador de MySQL va a ejecutar la consulta y en qué orden hará cada una de las partes, así como los índices a utilizar en cada paso.
Pero lo que más nos interesa es la columna ‘table’, que nos dirá todas las tablas implicadas en la query. Una vez localizadas todas ellas, procedemos a lanzar un OPTIMIZE TABLE de la siguiente forma:
OPTIMIZE TABLE <nombre_tabla>;OPTIMIZE TABLE ejecutará para tablas InnoDB un ALTER + ANALYZE reconstruyendo la tabla y reorganizando el almacenamiento en disco de sus datos y sus índices asociados.
Esto último es lo realmente interesante en este caso, puesto que una reorganización de los índices afecta de manera directa a la hora de elegir la “ruta más óptima” por parte de InnoDB durante las consultas SELECT. En otras palabras, la duración de las consultas se reducirá, o al menos ese es el objetivo.
La optimización puede durar desde unos segundos hasta muchas horas en el caso de tablas de un tamaño excepcional (la razón es que la tabla es regenerada completamente). Mientras este proceso se realiza, podemos situarnos en el directorio de datos de MySQL (por defecto /var/lib/mysql) e ir lanzando ls –lrt.
Veremos cómo la nueva tabla va creciendo mientras se regenera:
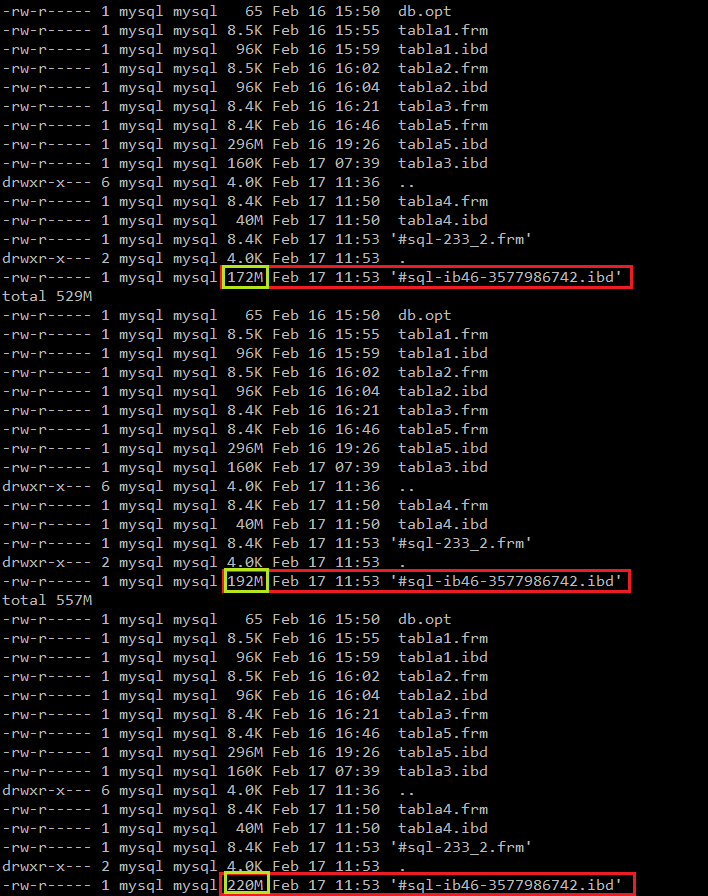
De esta forma, si conocemos el tamaño total de la tabla, podemos hacer una estimación de cuándo finalizará la optimización.
Una vez finalizado el proceso, probamos a lanzar la misma query y observamos el tiempo de ejecución:

Como se puede observar, éste se ha reducido en algo más de un 15%. En nuestro caso, en este pequeño entorno de pruebas, se trata de una reducción de menos de un segundo, pero en casos reales que hemos tratado con clientes, hemos llegado a reducir el tiempo de ejecución en varios minutos al optimizar tablas cuya ocupación en disco era de varias decenas de gigabytes.
Planificación no óptima por errores en las estadísticas
Existe la opción remota de que las estadísticas no se estén generando correctamente y exista una cardinalidad errónea para ciertos índices, en cuyo caso, MySQL usará un índice menos óptimo o incluso ningún índice en parte de la ejecución.
Si nos encontramos con este caso, puede ser necesario modificar el valor de la variable innodb_stats_persistent_sample_pages para que en el cálculo de estadísticas se use un mayor número de páginas de muestra.
Una vez modificado dicho valor, debemos volver a ejecutar la optimización de la tabla y comprobar nuevamente con EXPLAIN si el planificador ha modificado cómo se ejecutará la consulta usando otros índices.
Conclusión
Unos tiempos de ejecución rápidos en las queries son fundamentales para el mejor funcionamiento posible de nuestras bases de datos y, por consiguiente, de nuestros aplicativos.
Esperamos que este artículo os haya servido para aprender algo nuevo con respecto al funcionamiento interno de MySQL y sobre cómo acelerar nuestras consultas en bases de datos.
¡ Hasta la próxima ;) !