

pg_dump y pg_restore: opciones y eficiencia de backups en PostgreSQL
Si has llegado aquí es porque te interesan los backups de PostgreSQL ¡Normal!
Se trata de la base de datos que más interés genera a los desarrolladores según la última encuesta anual de StackOverflow. Para tal fin, dentro del conjunto de herramientas existentes, contamos con las herramientas nativas pg_dump y pg_restore.
Éstas facilitan la exportación de datos y su posterior importación, por ello, se utilizan en tareas de copia de seguridad y migraciones.
Es importante tener en mente cuando hablamos de backups que, dando por supuesto la fiabilidad de los mismos, hay dos variables importantes a tener en cuenta siempre:
- El espacio en disco que ocupan los backups. Esto tiene impacto directo en el coste de los mismos, especialmente si tenemos una política de backups de alta retención.
- El tiempo de realización de dichos backups, sobre todo de su recuperación. Cuando recuperamos un backup por alguna incidencia, lo habitual es que nos falte tiempo.
En este artículo vamos a ver algunas de sus opciones en lo que se refiere a formato de exportación, compresión y pruebas sobre los mismos.
Volcado de datos
Para llevar a cabo un dump o volcado de los datos, utilizamos pg_dump.
Una de las funcionalidades más interesantes de esta herramienta es que nos permite elegir el formato que se va a utilizar para el dump utilizando la opción -F.
Disponemos de los siguientes:
- p plain
- c custom
- d directory
- t tar
Con plain obtenemos un fichero en plano con el SQL necesario para la creación de todos los objetos de la bbdd y sus datos.
Esta es la opción por defecto y a la que estamos acostumbrados de otras bases de datos, como por ejemplo con mysqldump de MySQL. Utilizando este formato también se puede comprimir directamente con GZIP, haciendo uso de la opción -Z y el nivel de compresión que queramos del 0 al 9.
Para la carga de estos datos no es necesaria ninguna herramienta especial, se puede volcar directamente las sentencias SQL a la base de datos deseada.
Directory nos permite realizar el volcado de datos creando un directorio con un fichero por cada tabla.
Este formato utiliza compresión por defecto y es necesario usar pg_restore para la importación de los datos. Este formato permite la carga paralela del dump.
El formato tar simplemente genera un archivo tar. Desempaquetando uno de estos archivos obtenemos el contenido en el formato directory. Este formato también necesita de pg_restore para la importación y no es compatible con la compresión.
Por último, pero no menos importante, el formato custom. Se trata de un formato propio de PostgreSQL que genera un único fichero. Está comprimido por defecto y requiere de pg_restore para la importación, permitiendo la carga paralela del dump.
Hemos llevado a cabo pruebas para comprobar la diferencia de tamaño y tiempo resultante de utilizar distintos formatos y niveles de compresión.
Nos hemos centrado en el formato plain y custom.
Para estas pruebas hemos utilizado la base de datos OMDB, que es una de las bases de datos de ejemplo que recomienda PostgreSQL en su wiki (estamos preparando pruebas con una base de datos más grande que publicaremos próximamente). Esta base de datos la hemos cargado en un PostgreSQL 13 corriendo sobre Debian 11 en una máquina virtual con 4 cores y 6GB de RAM.
Estos son los datos que hemos obtenido:
|
Comando |
Ocupación |
Tiempo de volcado |
Tiempo de carga |
|
pg_dump |
92MB |
1.199s |
5.343s |
|
pg_dump -Z0 |
92MB |
1.144s |
- |
|
pg_dump -Z1 |
36MB |
1.610s |
- |
|
pg_dump -Z9 |
31MB |
8.397s |
- |
|
pg_dump -Fc |
31MB |
4.407s |
4.978s |
|
pg_dump -Z0 -Fc |
106MB |
1.192s |
6.282s |
|
pg_dump -Z1 -Fc |
36MB |
1.702s |
5.064s |
|
pg_dump -Z2 -Fc |
35MB |
1.839s |
5.015s |
|
pg_dump -Z3 -Fc |
34MB |
2.281s |
5.000s |
|
pg_dump -Z4 -Fc |
33MB |
2.294s |
5.076s |
|
pg_dump -Z5 -Fc |
32MB |
3.058s |
5.019s |
|
pg_dump -Z6 -Fc |
31MB |
4.569s |
5.071s |
|
pg_dump -Z7 -Fc |
31MB |
5.292s |
5.072s |
|
pg_dump -Z8 -Fc |
31MB |
7.865s |
5.042s |
|
pg_dump -Z9 -Fc |
31MB |
8.513s |
5.033s |
De los datos anteriores podemos destacar:
- El formato custom de PostgreSQL sin comprimir ocupa más que el texto plano, tardando aproximadamente el mismo tiempo en el volcado, pero más en la carga. No obstante, este formato activa por defecto la compresión a nivel 6, lo cual hace que el tamaño se reduzca considerablemente manteniendo un tiempo de carga similar pero, 4 veces superior en el volcado.
- tiempos de carga de los ficheros en formato custom son semejantes incluso con niveles de compresión diferentes.
- Los tiempos de volcado y tamaños son semejantes entre el formato custom y plain, pero para la carga, en el caso del formato plain, si se ha utilizado compresión es necesario incluir un paso previo para descomprimir el archivo, algo que no es necesario con el formato custom
Carga de datos
Para la importación como ya hemos ido indicando se utilizan dos métodos distintos en función de cómo hemos realizado el volcado:
- Si disponemos del lo podemos cargar con psql, indicando la opción -f y el fichero, o bien, volcando el fichero con standard input.
- Si es cualquiera de los otros formatos es necesario utilizar pg_restore, indicando con la opción -d la base de datos.
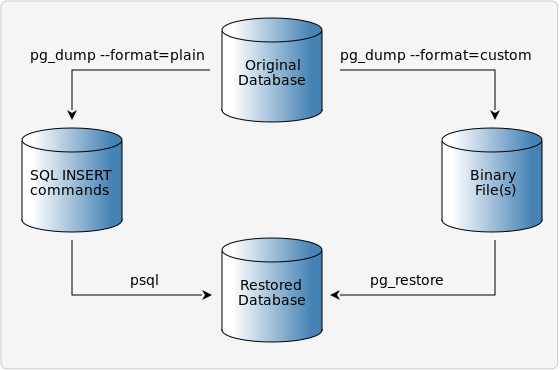
Imagen atribuida a Wikimedia Commons
Hemos mencionado anteriormente que algunos formatos permitían la carga paralela del dump. Esta es una funcionalidad de pg_restore que permite llevar a cabo los trabajos de importación que consumen más tiempo de forma concurrente.
Podemos indicar la concurrencia con la opción -j y el número de trabajos. Cada trabajo corresponde a un hilo y utiliza una conexión independiente a la base de datos.
El número de trabajos concurrentes óptimo para cada caso depende del hardware del que disponemos.
Una buena opción suele ser utilizar el mismo número o próximo de trabajos que cores disponibles en la máquina, no obstante se pueden obtener buenos resultados con valores mayores. En cualquier caso, un valor muy alto casi siempre será perjudicial debido a los cambios continuos de contexto.
Hemos realizado pruebas en el mismo entorno indicado anteriormente utilizando un dump en formato custom y con diversos valores de jobs. Hemos obtenido los siguientes resultados:
|
Comando |
Tiempo de carga |
|
-j1 |
5.092s |
|
-j2 |
3.068s |
|
-j3 |
2.424s |
|
-j4 |
2.597s |
|
-j5 |
2.813s |
|
-j6 |
2.942s |
Lo que vemos en nuestro caso es que la carga más eficiente se ha llevado a cabo al indicar 3 jobs, es decir, uno por debajo del número de cores disponible.
Estos tiempos dependen en gran medida del hardware concreto que se está utilizando para la carga y de la base de datos. Por ello, si se quiere saber cuál es el valor más eficiente para llevar a cabo por ejemplo una migración, lo más recomendable es realizar pruebas antes.
Conclusión
Las conclusiones que hemos sacado de estas pruebas es que si no se tiene un requisito concreto, lo más eficiente teniendo en cuenta el tiempo y ocupación, es llevar a cabo el volcado con el formato custom, la compresión por defecto y la carga indicando un número de jobs ligeramente inferior al número de cores disponible.
Estamos preparando una nueva batería de pruebas con una base de datos de mayor tamaño para comprobar si el comportamiento obtenido es diferente.
¡Estate atento porque en breve publicaremos los resultados!