

Troubleshooting de un pod en fallo desde el dashboard de Kubernetes
A todos nos ha pasado que levantamos un pod y, cuando revisamos su estado en el dashboard de Kubernetes, vemos que tanto el liveness probe como el readiness probe están fallando:

Y ahora, ¿qué?
Hay tantas cosas por revisar que dar con el fallo se puede convertir en una tarea en la que puedes desperdiciar horas, de las que muchas veces no disponemos.
En este artículo vamos a repasar algunas de las principales configuraciones a revisar y comprobaciones básicas a realizar para obtener pistas que nos ayuden a dar con el origen del fallo de un pod, asumiendo que ya hemos revisado los logs del propio pod y no nos están ayudando.
Darle "oxígeno" al pod
Una de las cosas que puede estar ocurriendo es que ambos probes se estén iniciando demasiado pronto y, cuando estos hacen sus peticiones, el servicio aún no está listo para responder.
Así pues, lo primero que podemos hacer es irnos al Deployment y revisar los valores que le habíamos puesto al initalDelaySeconds de ambos probes:
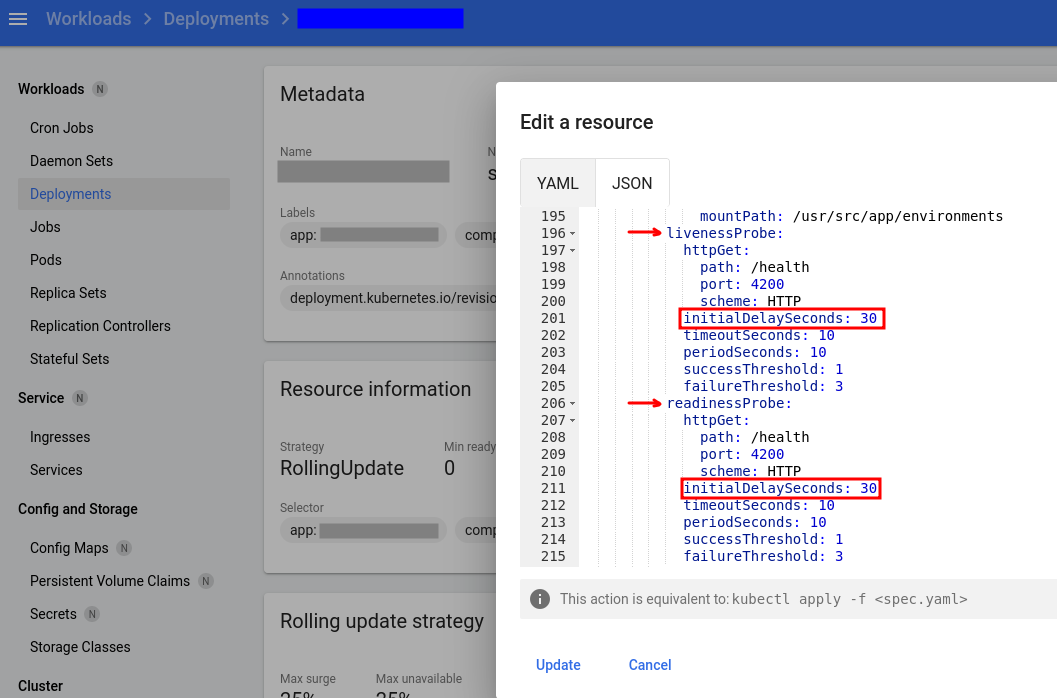
En este caso concreto está configurado para que ambos probes realicen la comprobación a los 30 segundos de levantar el pod.
Es posible que nuestro servicio no esté listo 30 segundos después de haberse levantado el pod, y es por esto que la comprobación falla. Podemos ajustar el valor a, por ejemplo,300 segundos (5 minutos), dándole así suficiente “oxígeno” al pod para que inicie tranquilamente todos sus servicios antes de que lleguen los probes con sus exigencias.
Ir al origen
Si el error se está produciendo dentro del pod, ¿Por qué no entrar en él para verificar de primera mano?
Aunque los queridos manuales de buenas prácticas no lo recomiendan de manera general, si es un pod que no está en servicio y tampoco vamos a realizar modificaciones dentro de él, sino, simplemente lanzar comandos de verificación, no deberíamos tener demasiado reparo en hacerlo.
¿Y qué comprobaciones se pueden hacer?
Pues, por ejemplo: sabiendo que los probes están atacando al puerto 80, ¿tenemos dicho puerto en escucha?

¿Qué pasa si hago un curl a dicho puerto y al path /health que es al que realizan la petición los probes?
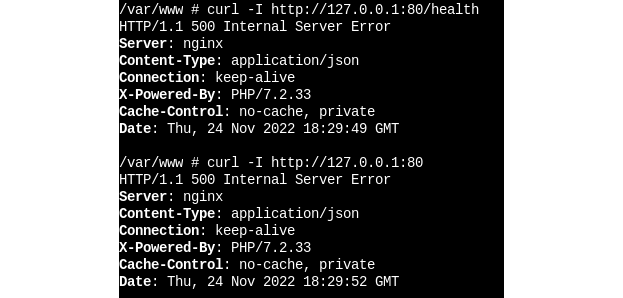
Este último ejemplo nos aporta un dato muy interesante. El curl está devolviendo un 500. Por lo tanto, el servicio nginx está arrancado, pero algo no está funcionando como debería. Esto puede ser una pista de que hay que revisar la imagen y corregir configuraciones de nginx y/o sus vhosts.
Revisar Config Maps y Secrets
En STR casi nunca tocamos directamente sobre las consolas y dashboards (como nos gusta llamarlo: “el clicky-clicky”), sino que, lo tenemos todo en repos automatizado y realizamos cambios mediante ejecuciones de Ansible.
Si este es también vuestro caso, no está de más revisar qué se ha configurado en los Config Maps y los Secrets tras lanzar la automatización:
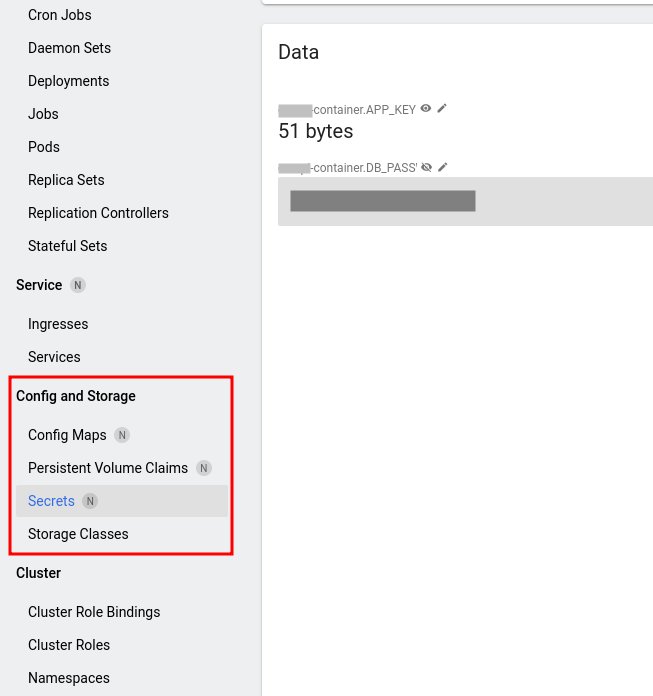
¿Son correctos los valores de las variables? ¿Se corresponden con lo que tenemos en el repo? Si usamos EKS, ¿las access key de AWS son correctas? Si la aplicación conecta con una base de datos, ¿es correcta la contraseña?
Hay veces que cometemos errores (typos) y se nos cuela un carácter de más (o de menos), o utilizamos algún tipo de encriptación de por medio y la información llega corrupta al destino.
¿Y si el fallo está fuera de Kubernetes?
En una ocasión nos pasó que le dedicamos tiempo a tratar de averiguar por qué fallaba el servicio de un pod. Al final resultó ser que dicho servicio conectaba con un RDS y no habíamos definido correctamente los permisos para un usuario de base de datos, concretamente el host desde el que tenía permitido conectar.
En muchas ocasiones el problema no se encuentra dentro de Kubernetes, sino fuera, como en este caso que acabamos de comentar. Tenemos que dedicar unos minutos a pensar qué hace el servicio, a dónde conectan los aplicativos, etc.
Conclusión
Esperamos que estos tips os sirvan de guía para ordenar ideas y realizar comprobaciones básicas.
Recordad que cada aplicación es un mundo y, en vuestro caso concreto, la solución no pase por realizar ninguna de las acciones comentadas a lo largo de este artículo.
Sea como sea, esperamos que consigáis ver el color que todo sysadmin quiere ver en sus clusters: el verde.

¡Hasta la próxima!