

Unassigned shards y watermarks de Elasticsearch
Elasticsearch es un motor de búsqueda y analítica distribuido, gratuito y abierto para todos los tipos de datos, incluidos textuales, numéricos, geoespaciales, estructurados y no estructurados. Está desarrollado a partir de Apache Lucene y fue presentado por primera vez en 2010. Elasticsearch es el componente principal del Elastic Stack (ELK Stack), compuesto por Elasticsearch, Logstash y Kibana, que permite la ingesta, el enriquecimiento, el almacenamiento, el análisis y la visualización de datos.
Por su parte, Kibana es una aplicación de frontend que proporciona capacidades de visualización de datos y de búsqueda para los datos indexados en Elasticsearch, además de otras tareas de administración. Logstash es el software encargado de la ingesta, transformación y envío de los datos, en este caso a Elasticsearch.
Elasticsearch utiliza shards, primarios y réplicas, para distribuir la información por los nodos del cluster y conseguir alta disponibilidad. Cuenta con una API para obtener información sobre la salud del cluster, siendo éste el parámetro principal, que cambia de valor en función del estado de los shards primarios y sus réplicas. Hay tres estados posibles:
- Green: es el estado normal de funcionamiento del cluster e indica que todos los shards están asignados.
- Yellow: todos los shards principales están asignados pero hay uno o más shards de réplica que no. En este caso el cluster funciona con normalidad, pero con el fallo de alguno de los nodos, parte de los shard podrían quedarse sin ninguna réplica disponible.
- Red: uno o más shards de primarios no están asignado, por lo tanto, siempre hay información no disponible en este estado y ciertas operaciones en el cluster no funcionarán correctamente.
Es habitual encontrar el cluster en estado yellow cuando, por ejemplo, se ha reiniciado uno de los nodos durante el proceso de arranque del mismo. Otra de las principales causas de un cluster en estado yellow, y que vamos a tratar en este artículo, es la ocupación de disco.
Para comprobar el estado del cluster lo podemos hacer desde Kibana o atacando a la API anteriormente mencionada. Para ello, tenemos que lanzar una petición al cluster (en este caso suponemos que lo realizamos desde uno de los nodos y se utiliza el puerto estándar):
curl -XGET 'http://localhost:9200/_cluster/health?pretty'
Si nos devuelve un estado yellow ya sabemos que tiene que haber por lo menos un shard de réplica sin asignar. Podemos obtener más información sobre los shards sin asignar con:
curl -XGET ‘http://localhost:9200/_cluster/allocation/explain?pretty’
De esta forma obtendremos los shards que no han sido asignados y la razón. Aunque hay múltiples motivos en este caso, vamos a centrarnos en la ocupación de disco.

Imagen: John Oxley Library, State Library of Queensland
Para prevenir un llenado de disco y posible pérdida de datos, Elasticsearch cuenta con varias propiedades de definición de watermark de disco para proteger el clúster. Hay tres valores principales a tener en cuenta:
- cluster.routing.allocation.disk.watermark.low: este valor indica el punto a partir del cual no se asignan nuevos shard en el nodo, por defecto es un 85%.
- cluster.routing.allocation.disk.watermark.high: este valor indica el punto a partir del cual el servicio tratará de reasignar los shards fuera del nodo afectado. El valor por defecto es 90%.
- cluster.routing.allocation.disk.watermark.flood_stage: el servicio activa un bloqueo de solo lectura, que además, permite borrados (index.blocks.read_only_allow_delete) en todos los indices que tengan uno o más shards asignados al nodo. El bloqueo se libera automáticamente cuando la ocupación se reduce de nuevo por debajo del watermark high. El valor por defecto es 95%.
Además de indicarse por porcentaje todas estas opciones se pueden configurar con un valor absoluto en bytes.
Por lo tanto, el hecho de llegar al watermark low en alguno de los nodos, nos puede desembocar en un cluster en estado yellow ante la imposibilidad de asignar nuevos índices al mismo. Lo correcto en este punto sería revisar si la ocupación es legítima o si se puede eliminar parte de la información del cluster liberando espacio. En caso de no ser posible, habrá que plantear aumentar el espacio de disco o número de nodos del cluster.
No obstante, durante estas acciones y para prevenir la indisponibilidad de alguno de los índices, también podemos modificar de forma temporal la configuración de watermarks en el transient. Esto se puede hacer con un PUT directamente desde Kibana en la consola de DevTools.
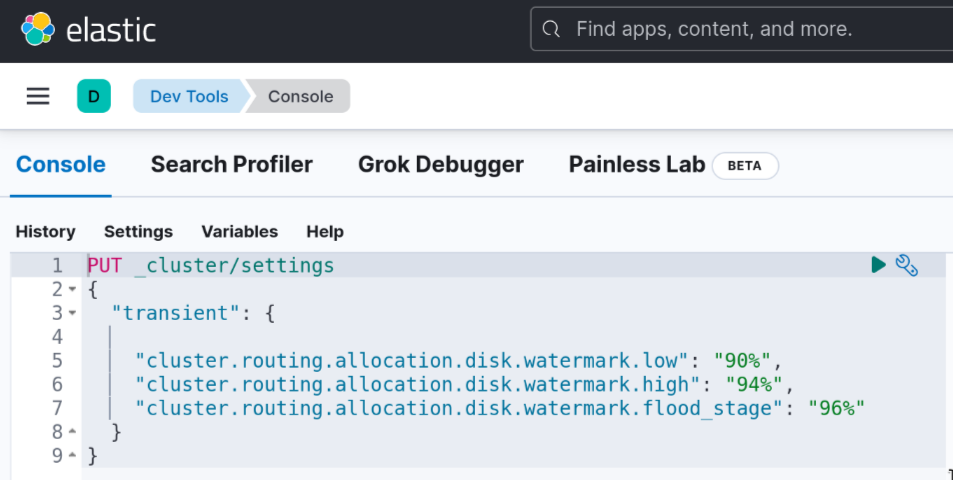
Las configuraciones transient se pierden tras el reinicio del servicio, por este motivo lo utilizamos en caso de querer hacer cambios temporales. No obstante, si tras llevar a cabo las acciones necesarias se decide modificar los niveles de watermark de forma permanente, había que hacerlo configurándolo como persistent.
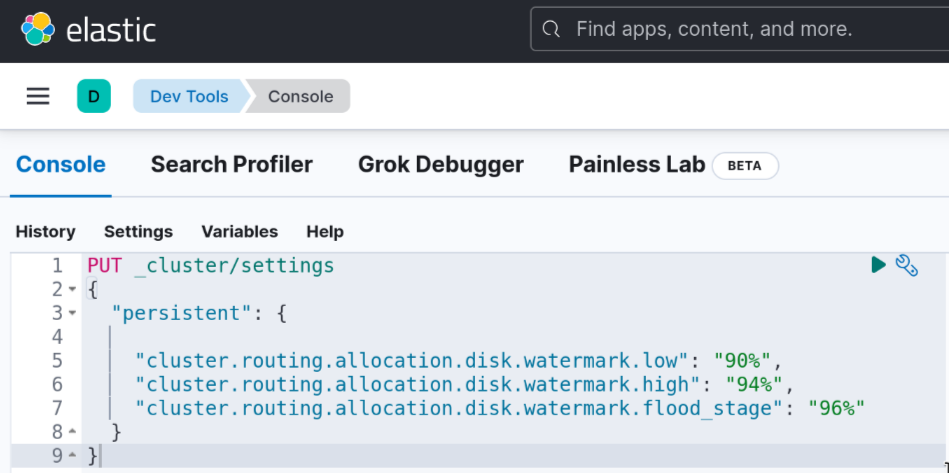
En este artículo hemos presentado solo uno de los motivos por los que podemos tener shards sin asignar en nuestro cluster. Es el más común, pero pueden darse otros casos como que haya un número de shards demasiado elevado. Por ello, es importante revisar el motivo concreto en la consulta del explain de allocation para tomar las medidas oportunas.